by Ed Nuhfer, Guest Editor, California State University (retired)
Steven Fleisher, California State University
Michael Roberts, DePauw University
Michelle Mason, University of Wyoming
Lauren Scharff, U. S. Air Force Academy
Ed Nuhfer, Guest Editor, California State University (retired)
This Appendix stresses numeracy and employs a dataset of 1734 participants from ten institutions to produce measures of cognitive competence, self-assessed competence, self-assessment accuracy, and mindset categorization. The database is sufficient to address essential issues introduced in our blogs.
Finding replicable relationships in noisy data employs groups from a database collected from instruments proven to produce high-reliability measures. (See Figure 10 at this link.). If we assemble groups, say, groups of 50, as shown in Figure 1 B, we can attenuate the random noise in individuals’ responses (Fig. 1A) and produce a clearer picture of the signal hidden within the noise (Fig. 1B).
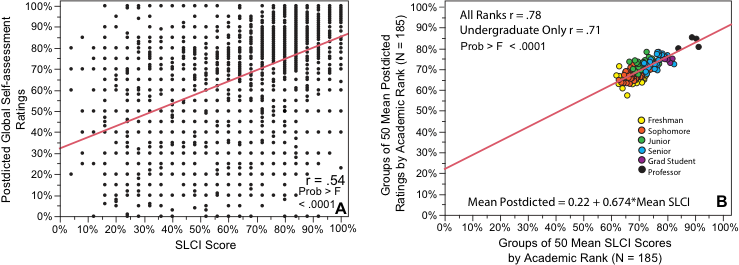
Figure 1 Raw data person-by-person on over 9800 participants (Fig. 1 A) shows a highly significant correlation between measures of actual competence from SLCI scores and postdicted self-assessed competence ratings. Aggregating the data into over 180 groups of 50 (Fig. 1 B) reduces random noise and clarifies the relationship.
Random noise is not simply an inconvenience. In certain graphic types, random noise generates patterns that do not intuitively appear random. Researchers easily interpret these noise patterns as products of a human behavior signal. The “Dunning-Kruger effect” appears built on many researchers doing that for over twenty years.
Preventing confusing noise with signal requires knowing what randomness looks like. Researchers can achieve this by ensuring that the surveys and test instruments used in any behavioral science study have high reliability and then constructing a simulated dataset by completing these instruments with random number responses. The simulated population should equal that of the participants in the research study, and graphing the simulated study should employ the same graphics researchers intend to present the participants’ data in a publication.
The 1734 participants addressed in Parts 1 and 2 of this blog’s theme pair on mindset are part of the larger dataset represented in Figure 1. The number is smaller than 9800 because we only recently added mindset questions.
The blog containing this Appendix link showed the two methods of classifying mindset as consistent in designating growth mindset as associated with higher scores on cognitive measures and more accurate self-assessments. However, this finding does not directly test how the two classification methods are related to one another. The fact noted in the blog that the two methods classified people differently indicated a reason to anticipate that the two may not prove to be directly statistically related.
We need to employ groups to attenuate noise, and ideally, we want large groups with good prospects of a spread of values. We first picked the groups associated with furnishing information about privilege (Table 1) because these are groups large enough to attenuate random noise. Further, the groups displayed highly significant statistical spreads when we looked at self-assessed and demonstrable competence within these categories. Note well: we are not trying to study privilege aspects here. Our objective, for now, is to understand the relationship between mindset defined by agree-disagree items and mindset defined by requests for feedback.
We have aggregated our data in Table 1 from four parameters to yield eight paired measures and are ready to test for relationships. Because we already know the relationship between self-assessed competence and demonstrated competence, we can verify whether our existing dataset of 1734 participants presented in 8 paired measures groups is sufficient to deduce the relationship we already know. Looking at self-assessment serves as a calibration to help answer, “How good is our dataset likely going to be for distinguishing the unknown relationships we seek about mindset?”
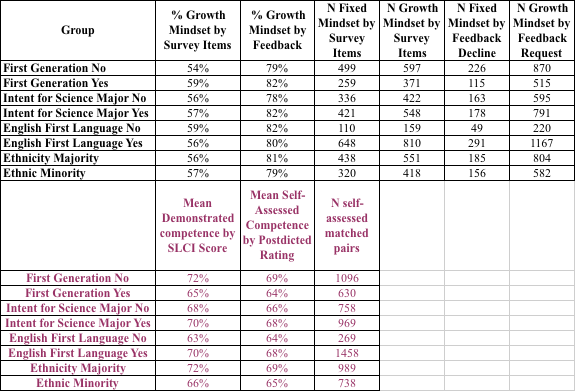
Table 1. Mindset and self-assessment indicators by large groups. The table reveals each group’s mindset composition derived from both survey items and feedback and the populace size of each group.
Figure 2 shows that our dataset in Table 1 proved adequate in capturing the known significant relationship between self-assessed competence and demonstrated competence (Fig. 2A). The fit-line slope and intercept in Figure 2A reproduce the relationship established from much larger amounts of data (Fig. 1 B). However, the dataset did not confirm a significant relationship between the results generated by the two methods of categorizing people into mindsets (Fig. 2B).
In Figure 2B, there is little spread. The plotted points and the correlation are close to significant. Nevertheless, the spread clustered so tightly that we are apprehensive that the linear relationship would replicate in a future study of a different populace. Because we chose categories with a large populace and large spreads, more data entered into these categories probably would not change the relationships in Figure 2A or 2B. More data might bump the correlation in Figure 2B into significance. However, this could be more a consequence of the spread of the categories chosen for Table 1 than a product of a tight direct relationship between the two methods employed to categorize mindset. However, we can resolve this by doing something analogous to producing the graph in Figure 1B above.
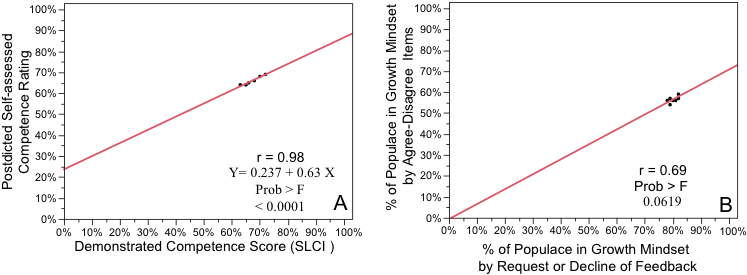
Figure 2. Relationships between self-assessed competence and demonstrated competence (A) and growth mindset diagnosed by survey items and requests for feedback (B). The data graphed is from Table 1.
We next place the same participants from Table 1 into different groups and thereby remove the spread advantages conferred by the groups in Table 1. We randomize the participants to get a good mix of the populace from the ten schools, sort the randomized data by class rank to be consistent with the process used to produce Figure 1B and aggregate them into groups of 100 (Table 2).
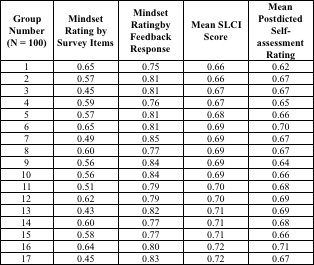
Table 2. 1700 students are randomized into groups of 100, and the means are shown for four categories for each group.
The results employing different participant groupings appear in Figure 3. Figure 3A confirms that the different groupings in Table 2 attenuate the spread introduced by the groups in Table 1.
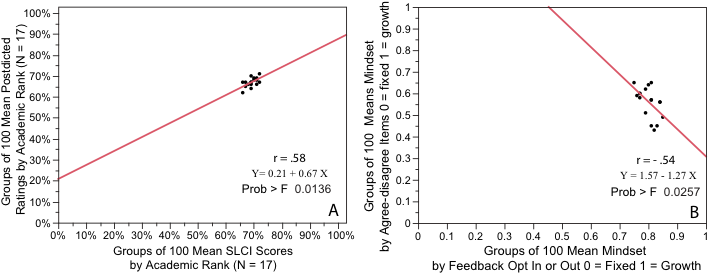
Figure 3. The data graphed is from Table 2. Relationships between self-assessed competence and demonstrated competence appear in (A). In (B), plotting classified by agree-disagree survey items versus mindset classified by requesting or opting out of feedback fails to replicate the pattern shown in Figure 2 B
The matched pairs of self-assessed competence and demonstrable competence continue in Figure 3A to reproduce a consistent line-fit that despite diminished correlation that still attains significance like Figures 1B and 2A.
In contrast, the ability to show replication between the two methods for categorizing mindsets has completely broken down. Figure 2B shows a very different relationship from that displayed in 1B. Deducing the direct relationship between the two methods of categorizing mindset proves not replicable across different groups.
To allow readers who may wish to try different groupings, we have provided the raw dataset used for this Appendix that can be downloaded from https://profcamp.tripod.com/iwmmindsetblogdata.xls.
Takeaways
The two methods of categorizing mindset, in general, designate growth mindset as associated with higher scores on tests of cognitive competence and, to a lesser extent, better self-assessment accuracy. However, the two methods do not show a direct relationship with each other. This indicates the two are addressing different dimensions of the multidimensional character of “mindsets.”